Now Available in Production Frameworks
Now Available in Production Frameworks
Speculative decoding is widely adopted to reduce latency in large language model (LLM) inference by leveraging smaller draft models capable of handling diverse user tasks. However, emerging AI applications, such as LLM-based agents, present unique workload characteristics: instead of diverse independent requests, agentic frameworks typically submit repetitive inference requests, such as multi-agent pipelines performing similar subtasks or self-refinement loops iteratively enhancing outputs. These workloads result in long and highly predictable sequences, which current speculative decoding methods do not effectively exploit.
To address this gap, we introduce SuffixDecoding, a novel method that utilizes efficient suffix trees to cache long token sequences from prompts and previous outputs. By adaptively speculating more tokens when acceptance likelihood is high and fewer when it is low, SuffixDecoding effectively exploits opportunities for longer speculations while conserving computation when those opportunities are limited.
Evaluations on agentic benchmarks, including SWE-Bench and AgenticSQL (a multi-agent SQL generation workflow), demonstrate that SuffixDecoding achieves speedups of up to 5.3×, outperforming state-of-the-art methods—2.8× faster than model-based approaches like EAGLE-2/3 and 1.9× faster than model-free approaches such as Token Recycling.
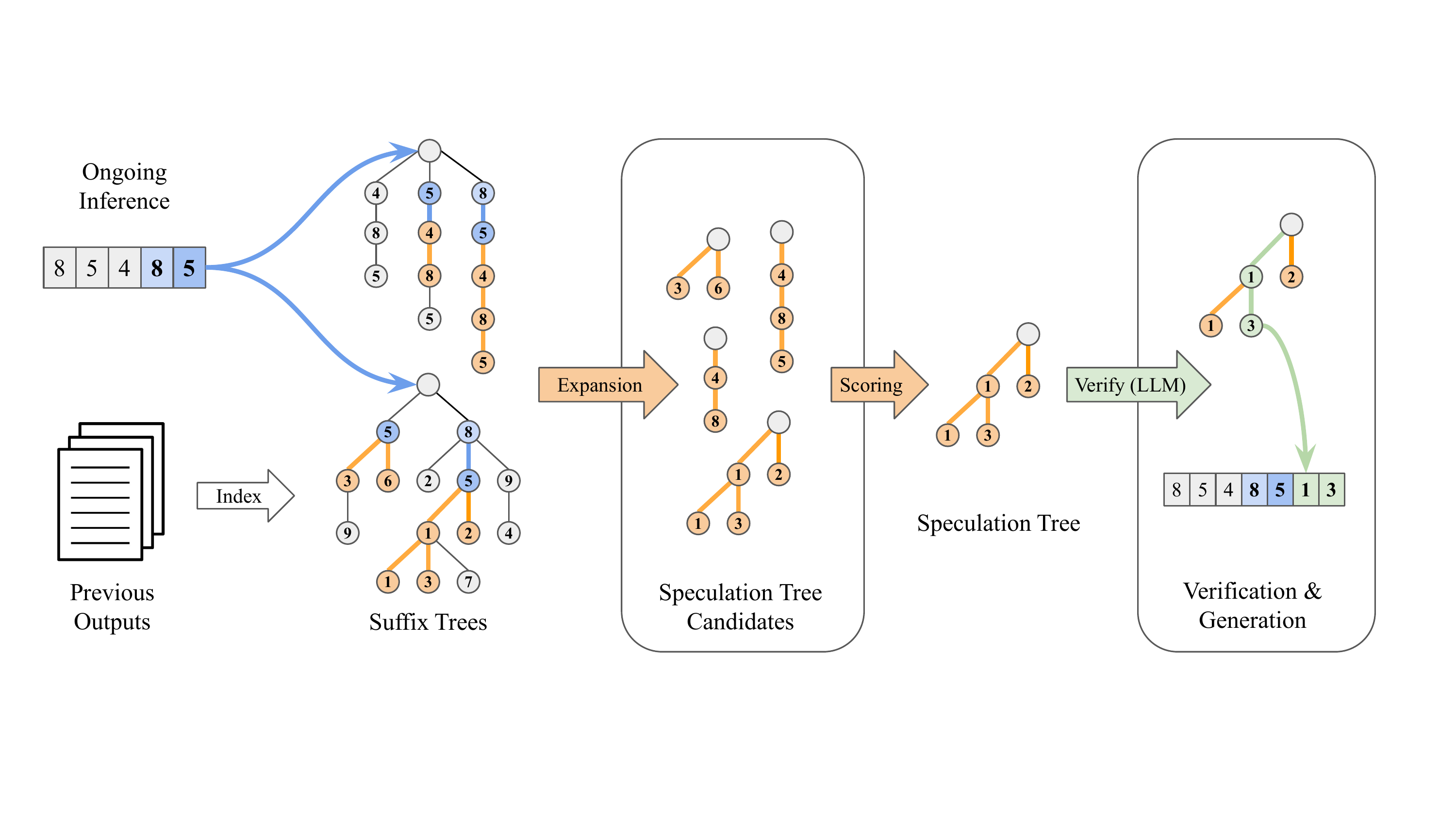
The goal of SuffixDecoding is to enable fast, adaptive speculative decoding over long sequences, particularly suited for agentic applications where repeated inference calls often contain highly predictable and overlapping token sequences. To support fast speculation, SuffixDecoding builds a suffix tree over the tokens in the current and prior requests, and uses the suffix tree to generate speculative tokens.
SuffixDecoding maintains two different suffix trees: a global tree for previously generated outputs, and a separate per-request tree for the current ongoing inference request. This circumvents the complexities and overheads due to synchronizing suffix tree updates from multiple concurrent requests. The global tree can be constructed offline in O(n) time, while the per-request tree can be efficiently constructed and updated online.
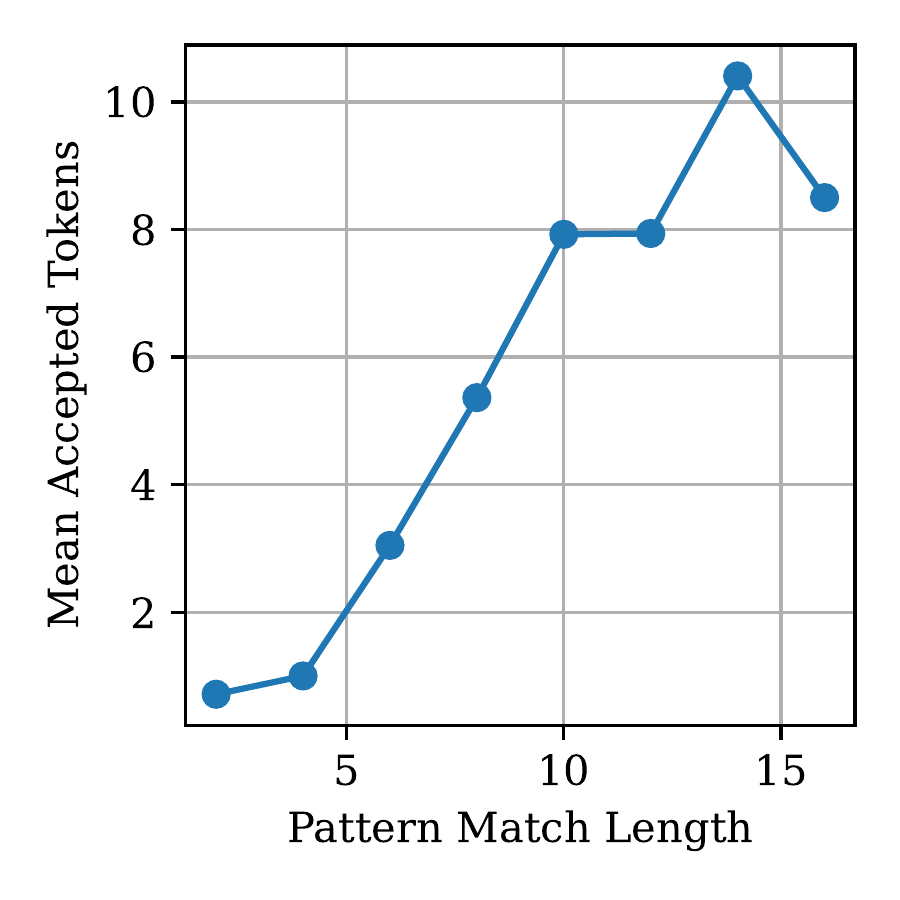
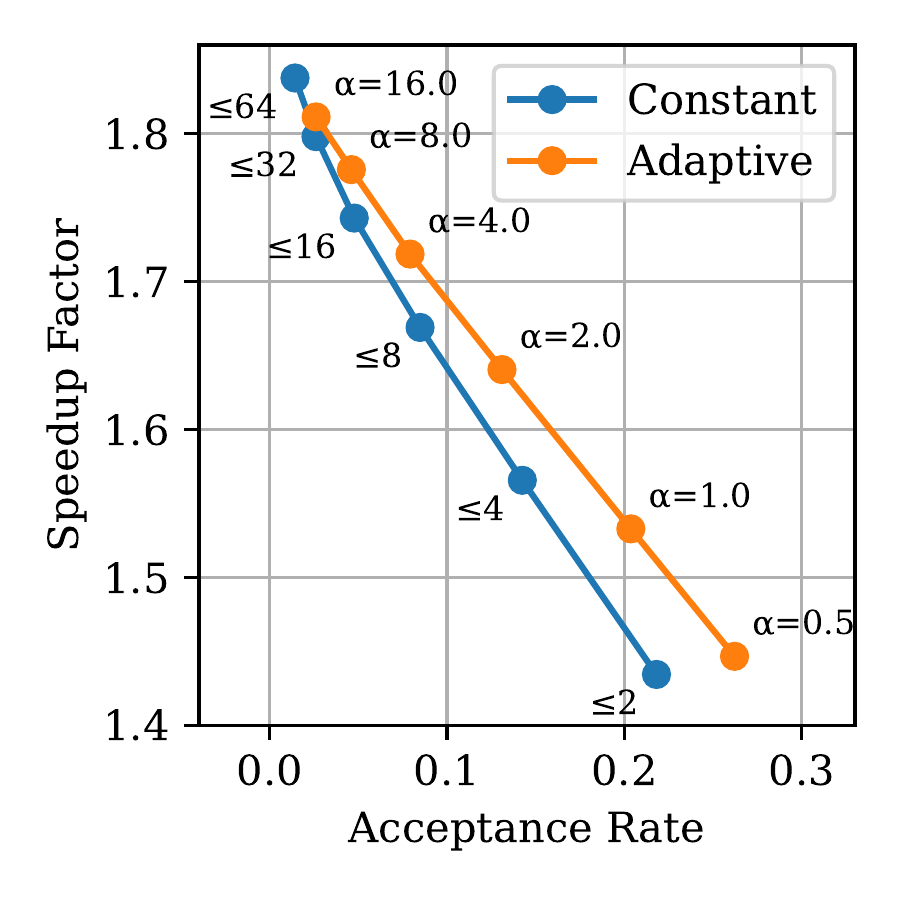
Left: The mean number of accepted tokens increases with the length of the pattern match, which motivates MAX_SPEC = αp. Right: Using an adaptive MAX_SPEC achieves a better trade-off between acceptance rate and speculative speedup compared to a constant MAX_SPEC.
The key innovation is adaptive speculation: SuffixDecoding dynamically adjusts the number of speculated tokens based on the quality of matches found in the suffix tree. When the method detects strong pattern repetition, it speculates aggressively (up to hundreds of tokens), maximizing parallelism in verification. When patterns are less predictable, it reduces speculation to avoid wasted computation.
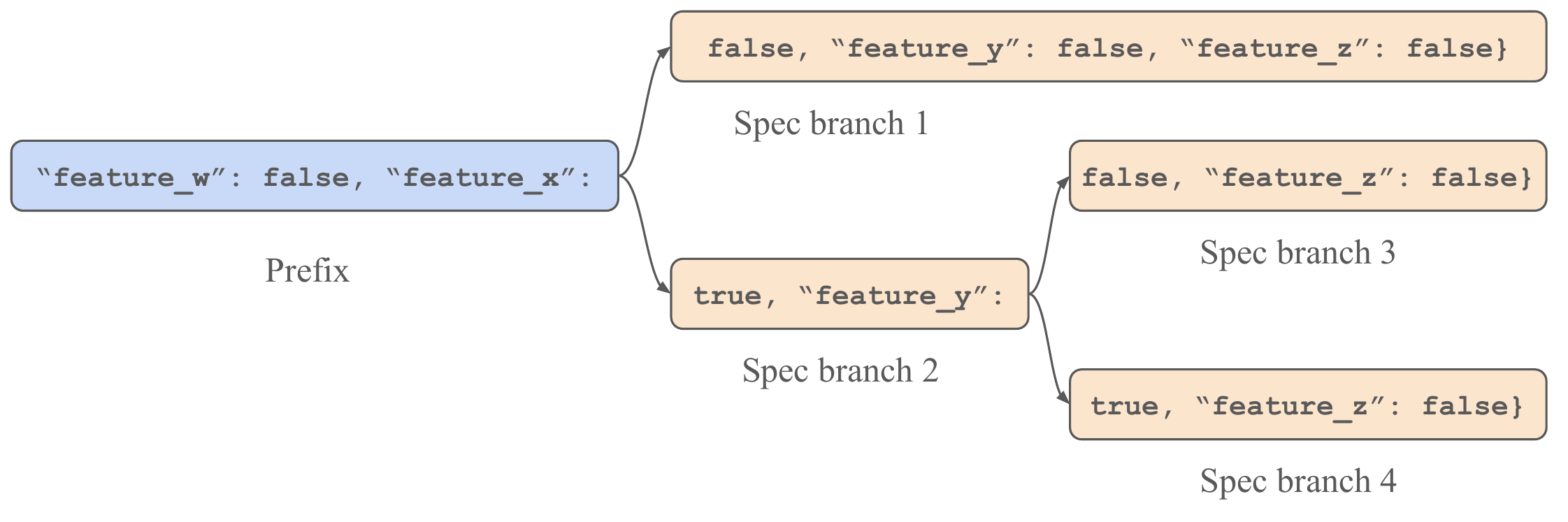
Example speculation tree containing 66 tokens for the AgenticSQL Extract task. SuffixDecoding builds the speculation tree by greedily adding leaf nodes that it believes to be the most likely to be accepted during verification, based on frequency statistics captured within the suffix trees.
To select a smaller more likely sub-tree for practical speculative verification, SuffixDecoding starts with a pattern match node and grows a sub-tree greedily by expanding one leaf node at a time. The method uses empirical probability estimates to score each potential expansion and selects the nodes most likely to be accepted.
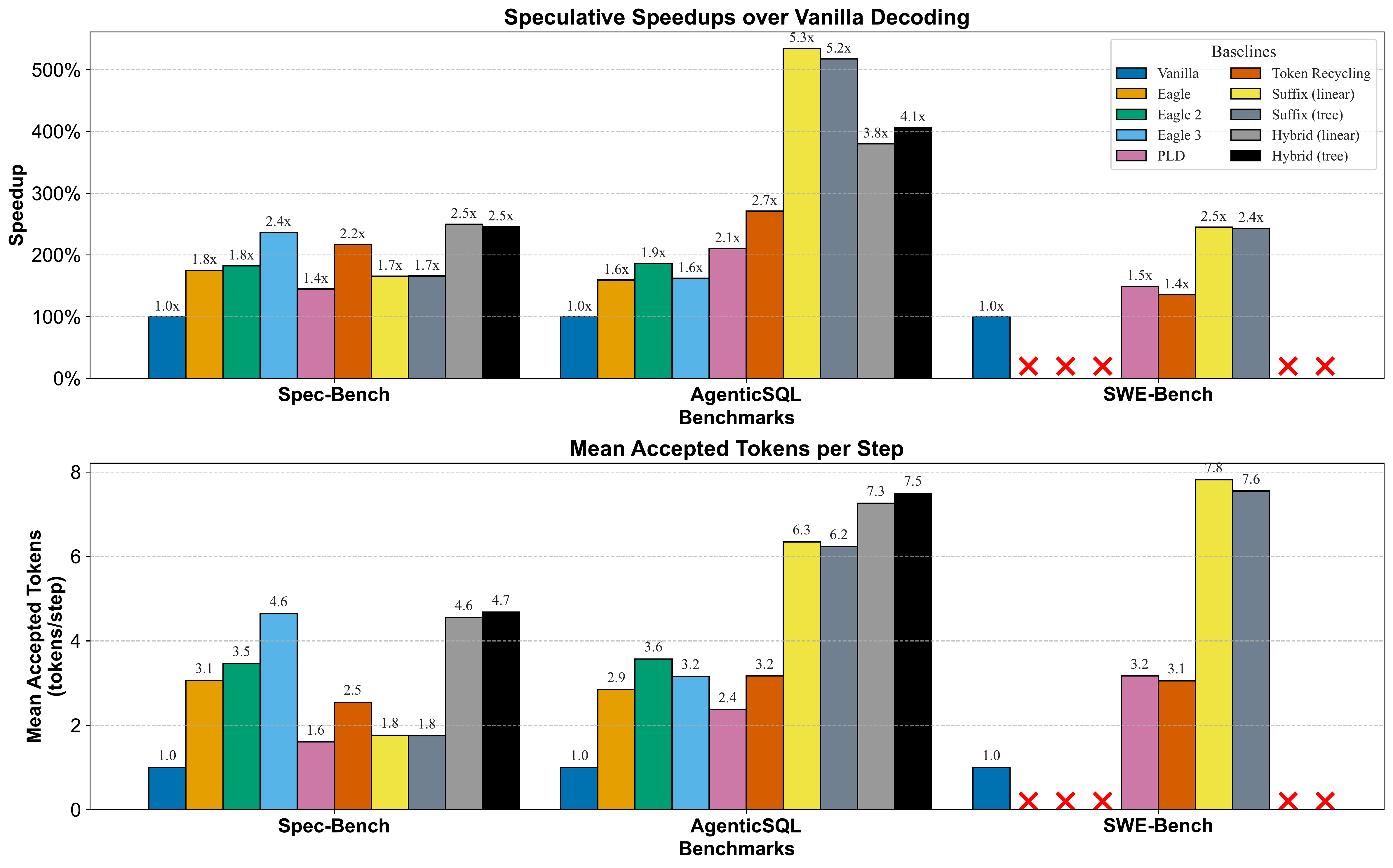
Speculative speedups (top) and mean accepted tokens per step (bottom) compared to vanilla decoding for SuffixDecoding and baseline methods on three benchmarks: Spec-Bench, AgenticSQL, and SWE-Bench.
On agentic workloads, SuffixDecoding outperforms all baselines. In AgenticSQL, SuffixDecoding obtains a mean speedup of 5.3× over vanilla decoding, a 2.8× improvement over EAGLE-2/3, and 1.9× higher than Token Recycling. In SWE-Bench, SuffixDecoding obtains a mean speedup of 2.5× over vanilla decoding and 1.7× improvement over Prompt-Lookup Decoding. SuffixDecoding's superior performance can be attributed to its consistently higher mean accepted tokens per decoding step.
The hybrid approach of SuffixDecoding + EAGLE-3 achieves the best of both worlds: we speculate with the faster SuffixDecoding method whenever possible and fall back to EAGLE-3 when the speculation score is too low. The hybrid approach performs well across both agentic and non-agentic workloads.
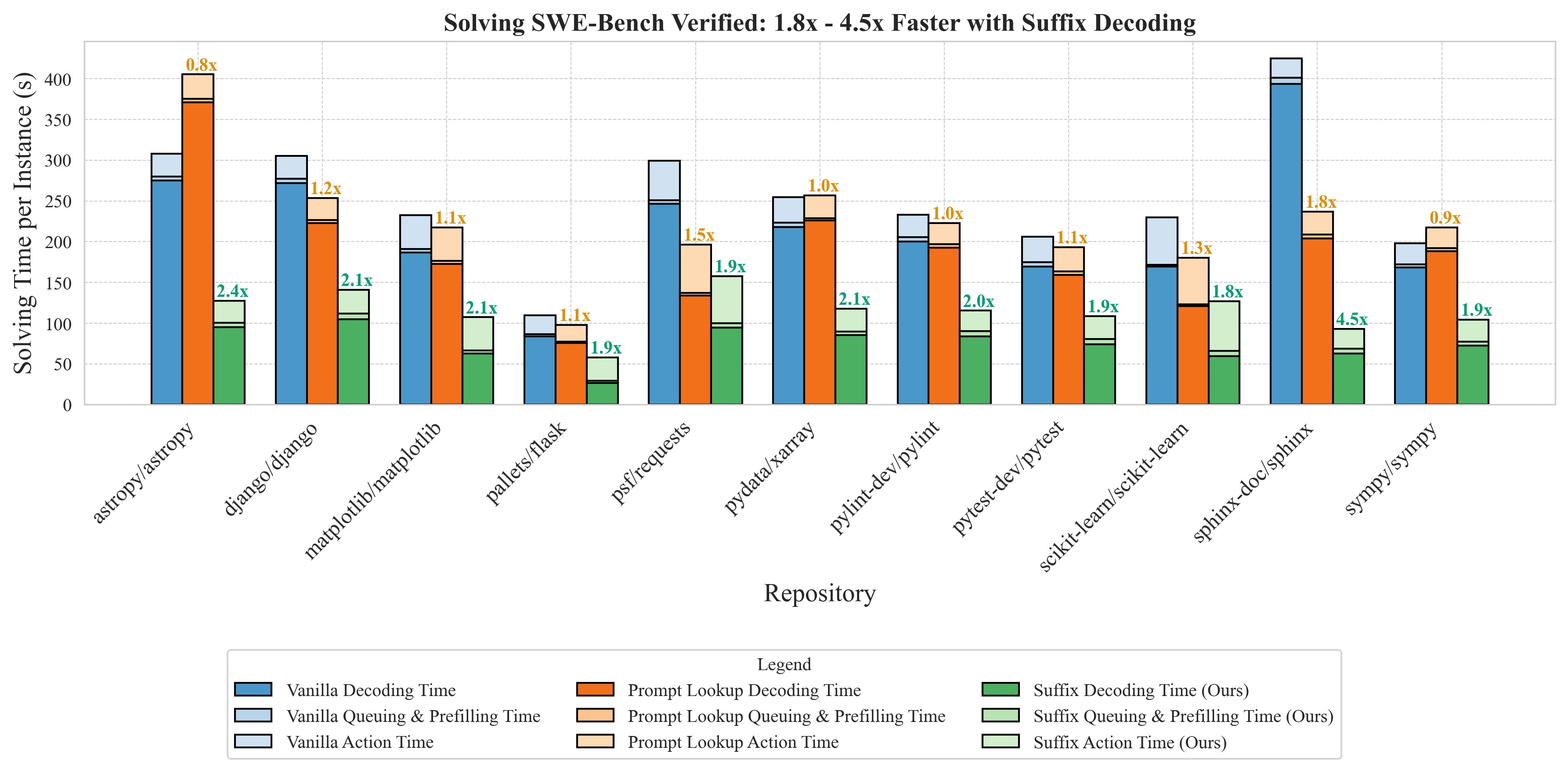
End-to-end task-completion time of the OpenHands agent on SWE-Bench Verified. The benchmarks are run with a concurrency of 8 tasks running simultaneously. vLLM is deployed on 4 H100 GPUs configured with 4-way tensor parallelism and prefix caching enabled.
SuffixDecoding can be efficiently integrated into vLLM, a popular inference system used in production deployments, and effectively accelerate end-to-end agentic task completion time. Decoding time (i.e. output generation) takes a majority of the time across all SWE-Bench tasks, dominating both prefilling and agentic actions. In this end-to-end scenario, SuffixDecoding outperforms PLD by 1.3–3×, leading to a 1.8–4.5× speculative speedup over vanilla decoding.

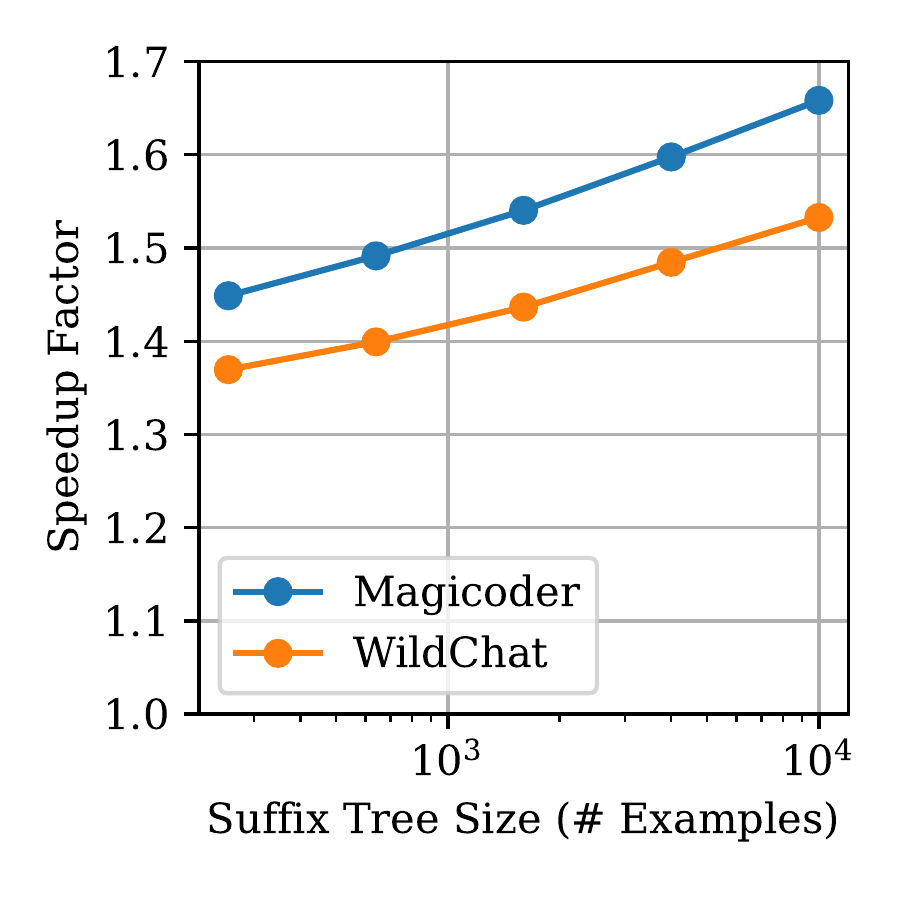
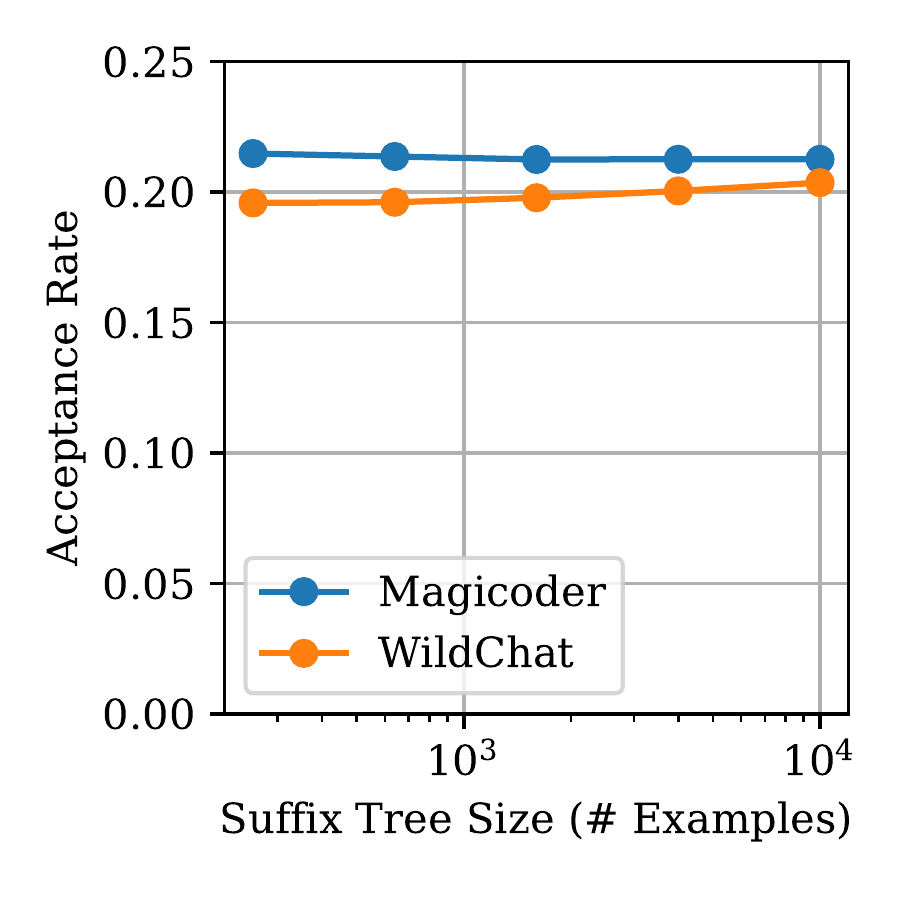
Top: Speedup factor for the tasks in AgenticSQL using only the global suffix tree, only the per-request suffix tree, and both. Bottom Left & Right: Speedup and acceptance rate vs global suffix tree size for Magicoder and Wildchat.
Ablation studies demonstrate the importance of each component in SuffixDecoding. Using both the global and per-request suffix trees performs better than using just one. The global tree outperforms the per-request tree on most tasks. Additionally, the speedup from SuffixDecoding continues to increase with more previous output examples, while the acceptance rate holds steady, indicating that SuffixDecoding can learn useful patterns even in workloads with lower token repetition.
SuffixDecoding is highly memory efficient. The suffix trees scale linearly with the number of cached tokens:
Lookup and update times remain fast (~4 microseconds per token for updates, ~12 microseconds for lookups) even with large trees.
SuffixDecoding adapts online to distribution shifts. In our experiments, when switching from WildChat to SpiderSQL (a significant distribution shift), SuffixDecoding initially achieves 1.5× speedup. However, it quickly adapts by inserting new outputs into its global suffix tree. After processing just 500 requests from the new distribution, SuffixDecoding's performance becomes almost indistinguishable from training on that distribution offline. This demonstrates strong online adaptation capabilities.
AgenticSQL is a proprietary multi-agent workflow designed for complex SQL generation tasks. It consists of multiple LLM-powered stages working together to convert natural language questions into accurate SQL queries.
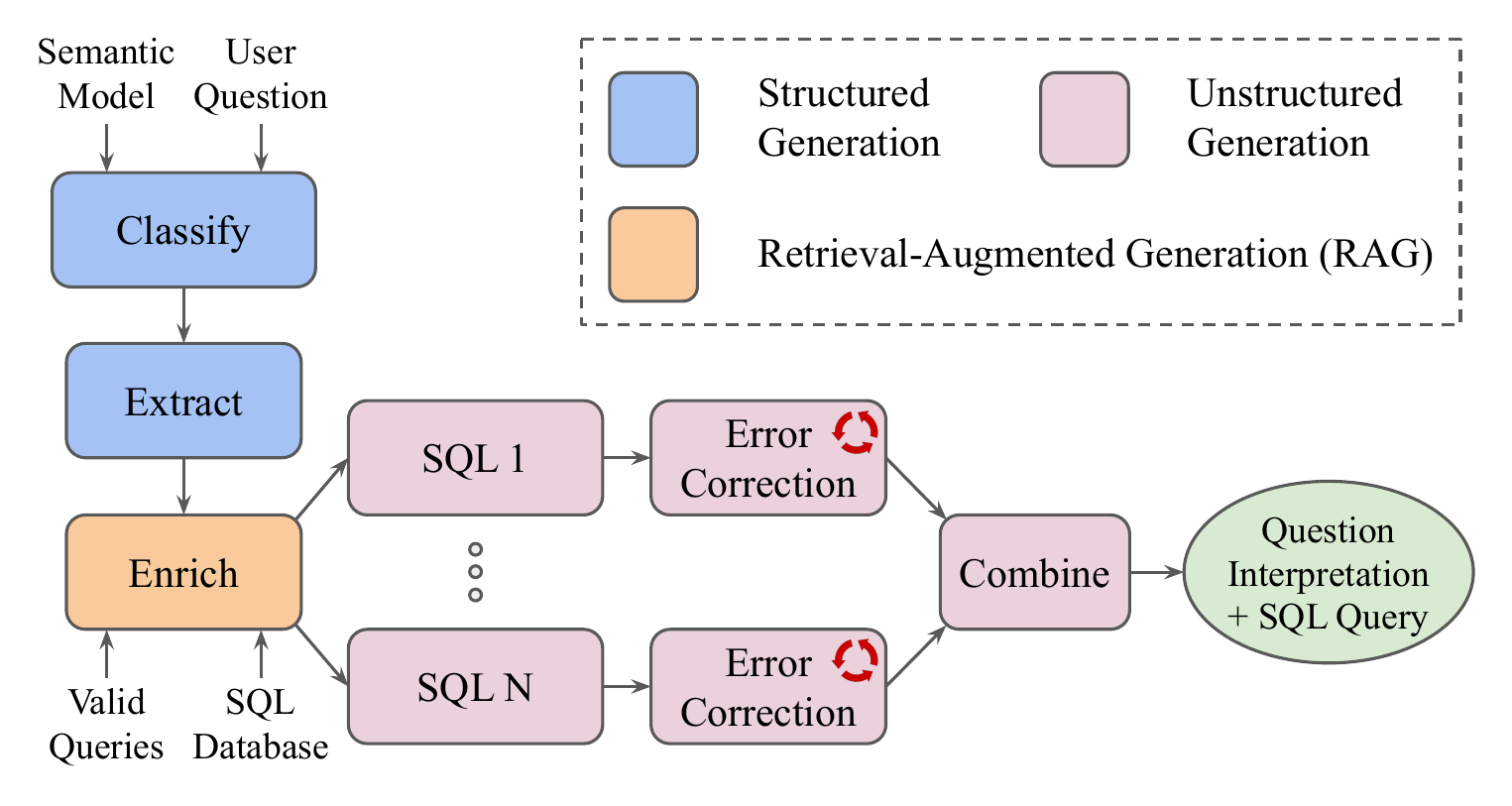
The workflow includes several specialized stages:
SuffixDecoding achieves exceptional performance on AgenticSQL (up to 10.41× speedup on the Enrich task and 9.85× speedup on Extract) because:
This demonstrates SuffixDecoding's strength on production agentic workflows where structured generation and repetitive patterns are common.
You can measure the "structuredness" of your task using empirical entropy with just 100 example outputs:
Lower average entropy indicates more predictable outputs and better SuffixDecoding performance. For reference:
The choice depends on your workload:
Yes! SuffixDecoding is compatible with batch-level speculation control methods like TurboSpec and AdaServe. By dynamically adjusting the number of speculative tokens per request based on the suffix tree scores, SuffixDecoding can be integrated to maximize batch-wise goodput or meet per-request SLO targets. The statistics-based scoring in SuffixDecoding can help determine which requests in a batch should receive more speculation budget.
Suffix tree construction is fast and only needs to be done once when starting the inference server:
This is a one-time cost, and the tree can be updated incrementally during serving with minimal overhead.
Yes! SuffixDecoding uses speculative decoding, which is mathematically guaranteed to preserve the exact output distribution of the target LLM. In our end-to-end vLLM experiments on SWE-Bench Verified, SuffixDecoding achieved the same 37.2% task completion rate as vanilla decoding while providing 1.8-4.5× speedup.
@inproceedings{oliaro2025suffixdecoding,
author = {Gabriele Oliaro and Zhihao Jia and Daniel Campos and Aurick Qiao},
title = {SuffixDecoding: Extreme Speculative Decoding for Emerging AI Applications},
booktitle = {The Thirty-ninth Annual Conference on Neural Information Processing Systems},
year = {2025},
url = {https://arxiv.org/abs/2411.04975}
}
{kind=link}